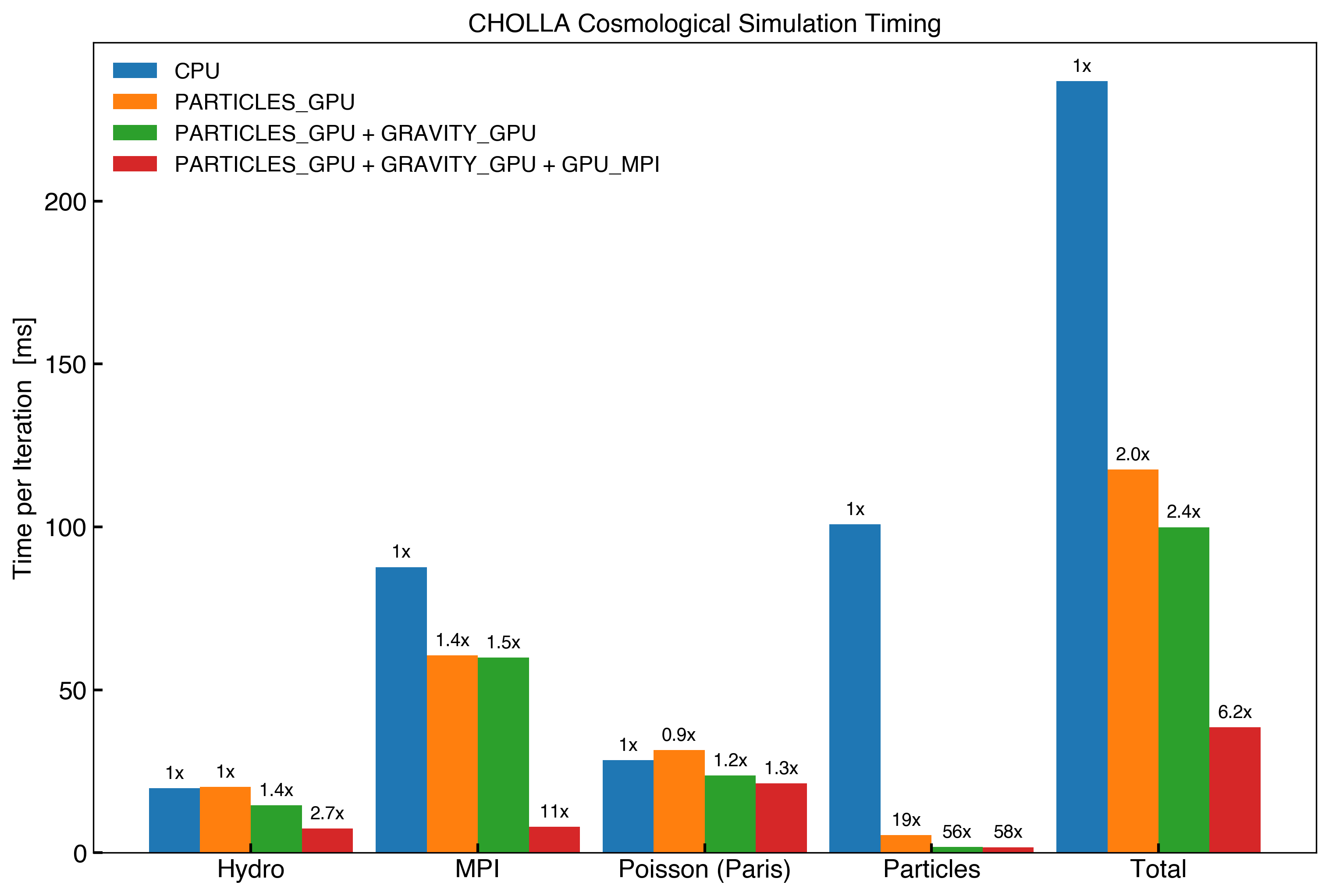
Timing for Optimized Cholla
Here I measure the average time per iteration for the different stages from a Cosmological Simulation run with Cholla.
The Simulation consists of \(256^3\) hydro cells and \(256^3\) DM particles running on Summit using 8 GPU’s. The times per iteration are averaged over the entire simulation from \(z=100\) to \(z=0\) (~1700 iterations in total).
The different configurations are:
CPU
- Hydro conserved data is evolved on the GPU but copied back and forward from and to the host every time-step.
- Poisson equation is solved on the GPU (Paris) but the density and potential are copied back and forward from and to the host every time-step.
- Particles are evolved on the host, each MPI porcess uses 7 OpenMP threads to do the particles computations.
- MPI boundary buffers for hydro, potential, particles density and particles transfers are loaded/unloaded on the host.
PARTICLES_GPU
- The particles are evolved entirely on the gpu.
- The particles density and particles transfer buffers are loaded/unloaded on the GPU and copied to the host for the MPI transfers.
- The particles density is copied from the GPU to the host.
GRAVITY_GPU
- Paris loads the density (hydro and particles) from the GPU and outputs the potential to the GPU, avoiding copies to the host.
- The potential boundary buffers are loaded/unloaded on the GPU and copied back to the host for the MPI transfers.
GPU_MPI
- The Hydro data is not copied back and forward to the host.
- The hydro boundary buffers are loaded/unloaded on the GPU and MPI transfered directly from the GPU.
- The potential boundary buffers are transfered directly from the GPU.
- The particles density boundary buffers and particles transfer buffers are transfered directly from the GPU.
The average times per iteration for the different stages are shown below. On top of each bar I show the performance increase of each configuration with respect to the CPU configuration.